
An Asset Allocator's AI Use Cases, Implementation Strategy, and Wishlist, with Mark Steed
Community Wisdom - Sharing the best that we find

“I want my team removed from high-volume, low-value tasks … so we can talk about what the information means.” — Mark Steed, CIO, Arizona Public Safety Personnel Retirement System
Introduction
After three direct one-on-one conversations with me in the interviewer seat, this note marks our first step into the Community Wisdom part of the program. This is where we curate the best and most practical material we find on how top investors and builders are incorporating AI into their processes and investment decisions.
I’m happy to share a recent interview I came across with Mark Steed, CIO of the Arizona Public Safety Personnel Retirement System. It took place on The Institutional Edge podcast, hosted by Angelo Calvello. What struck me almost immediately was Mark’s practical, level-headed approach. The absence of hyperbole is refreshing. Hopefully, we’ve done justice to the conversation between Angelo and Mark. What follows are the three styles of summaries we use, each offering a different angle on the material. Any mistakes herein are ours.
Lastly, the value we provide, hopefully, will come not only from the content and how it is presented, but also from introducing new, quality sources to your attention. In that spirit, I encourage you to check out The Institutional Edge, hosted by Angelo, and AI Street, published by former Bloomberg reporter Matt Robinson. It was in Matt’s weekly that I found this conversation. I find his newsletter a great top-of-funnel resource.
One of our motivations for starting AInvestor was to create a reason to actively engage with AI in an operational setting—learning by doing. I maintain active editorial oversight of instruction, model, and platform choices, but almost everything in the summaries below was written by AI. In the context of what we’re doing, I see this as a feature, not a bug. By experiencing the highs, and yes, the lows, we can better understand both the possibilities and the limitations of this new generation of AI.
Click above to access a custom GPT we spun up to help clean up our own writing. It’s designed to apply the lightest of touches. If you’re a paying ChatGPT customer, it’s free to use (we don’t get a cut). Feel free to play around with it as much as you’d like.
Learnings & Takeaways
In this interview, you’ll learn:
Why PSPRS focuses its AI program on two pillars: operational efficiency and decision-making.
How local, offline LLMs (e.g., Llama, Gemma) plus simple RPA handle secure document intake and field extraction.
Which unstructured-to-structured fields matter in PE diligence (partners, fund size/vintage, compliance officer, carry terms, portfolio metrics).
How ML improves predictions on small, non-normal, dependent datasets compared with classic linear models.
Where deep learning fits—pattern discovery in unstructured diligence—alongside human review.
What PSPRS’s governance looks like: decision logging, confidence calibration, human-in-the-loop, and parallel model vs. human runs.
How screening evolves toward a manager web portal once factor importance stabilizes with enough observations.
Why PSPRS runs on-prem first (security, cost) and what compute is required for large local models.
How team design (investing + data science) reduces bias and accelerates build-out.
Why PSPRS is skeptical of sentiment scraping as a trading edge amid flows, constraints, and misinformation.
Some takeaways:
Automate high-volume, low-value work to free humans for judgment. PSPRS targets doc retrieval, PDF parsing, field extraction, and first-draft memo generation so PMs spend time debating meaning, not chasing files.
Local LLMs solve near-term security and cost constraints. By running Llama/Gemma entirely offline and pointing models at staged repositories, PSPRS avoids sharing sensitive GP materials while proving value with quick R&D loops.
Structured outputs from PDFs are the backbone of the stack. Consistent extraction of partners, vintages, carry terms (with synonyms), compliance officers, and operating metrics feeds a queryable database that supports screening and attribution.
Use ML where statistical assumptions break. Small samples, non-normality, and dependence make linear regressions brittle; PSPRS applies ML to rank features and predict outcomes on structured data.
Treat deep learning as a black box—govern it accordingly. For unstructured packets, DL surfaces patterns, but PSPRS pairs it with calibration, clear decision scope, and parallel runs before granting decision authority.
Governance is a growth enabler, not a brake. Decision logging with explicit success criteria and confidence bands builds trust internally and with the board while de-biasing post-mortems.
Screening will shift to a portal with fewer, higher-signal fields. After enough observations, PSPRS will publish the handful of inputs that matter most, letting managers self-submit and enabling faster triage.
Right-size compute to the documents you actually read. A ~70B-parameter local model with ~96 GB RAM supports long filings and large context windows—enough for 10-Qs and data rooms without cloud exposure.
Blend backgrounds to reduce institutional bias. Pairing investors who learned data science with scientists learning investing keeps feature selection honest and problem framing grounded.
Be critical of sentiment feeds as alpha. Regulatory flows, rebalancing mechanics, and misinformation weaken any causal path from social sentiment to realized trades; PSPRS prioritizes verifiable, higher-signal data.
FAQs
Q1: What are PSPRS’s two primary AI use cases?
Operational efficiency and decision quality. Efficiency covers automated document intake (data rooms, PDFs), structured-field extraction, and first-draft memo generation. Decision quality covers ML on structured data and deep-learning pattern discovery in unstructured diligence materials, with calibration against stated confidence.
Q2: What specific efficiency wins are in scope right now?
Robotic access to proprietary portals (including two-factor workflows)
Bulk download of Private Placement Memorandums (PPMs), Due Diligence Questionnaires (DDQs), spreadsheets, filings
PDF/OCR parsing to extract fields (partners, portfolio metrics, fund size/vintage, compliance officer, carry terms)
Normalization into a queryable database
Auto-draft investment memos for human review
Q3: How is PSPRS handling data security?
Local-first. Large language models (LLMs) run on PSPRS machines, pointed at on-prem documents. No internet connection is required for extraction, fine-tuning, or memo drafts. Enterprise cloud will be evaluated after proof-of-concept success.
Q4: Which models and tools are being used?
Open-source LLMs such as Llama and Gemma for local use; Robotic Process Automation (RPA) scripts for retrieval; a house database for normalized fields; attribution tools (e.g., LIME/SHAP-style methods, activation maps) where interpretability helps.
Q5: What compute is required for the local LLM approach?
A high-memory workstation. For example, a ~70B-parameter model requires on the order of ~96 GB RAM to comfortably process long filings within a large context window.
Q6: What does the manager-selection workflow look like today?
Front-loaded quantitative requests to GPs, followed by model-assisted analysis of returned spreadsheets and data-room documents. Screening filters will tighten after enough observations establish which factors truly matter.
Q7: How will the external-facing data collection evolve?
A manager web portal is planned. Once factor importance stabilizes, PSPRS will publish a concise set of required fields so managers can self-submit the most predictive information up front.
Q8: How is explainability addressed?
Every material recommendation—human or model-assisted—includes success criteria and a confidence level. PSPRS tracks calibration (e.g., “80% confident” predictions should land near 80% realized accuracy). Interpretable models and attribution tools are used where practical.
Q9: What is the governance model?
Decision logging with explicit definitions of success
Calibration tracking across confidence bands
Human-in-the-loop for scope and overrides
Board education on a recurring cadence (semiannual planned)
Parallel runs for deep-learning decisions until performance is proven
Q10: How does PSPRS handle small samples and messy data?
By design. ML methods handle nonlinearity, non-normality, and dependence better than classic linear models. For alternatives, the pipeline converts unstructured PDFs into consistent rows, then builds evidence over time via calibration and parallel testing.
Q11: What is PSPRS’s stance on market sentiment analysis?
Skeptical. Flows, regulatory constraints, and misinformation weaken the link between surface sentiment and actual trades. Priority is on verifiable, higher-signal data tied to manager quality and portfolio fundamentals.
Q12: What KPIs matter for the efficiency program?
Cycle-time reduction (from data-room access to memo), throughput (docs/fields processed per day), staff hours saved, and first-draft memo quality (edit distance vs final).
Q13: What’s on the medium-term roadmap?
A multi-agent system:
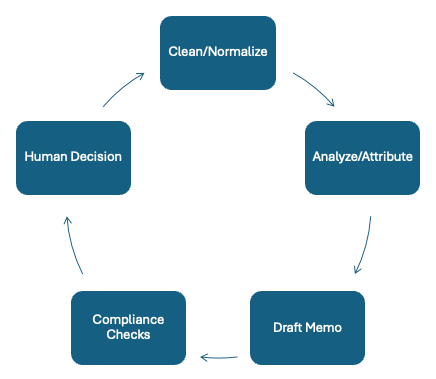
The goal is to remove low-value, high-volume work from the team and focus human time on judgment.
Q14: How are bias and overfitting mitigated?
Team design blends investment and data-science backgrounds to challenge assumptions. Feature sets are constrained to auditable, repeatable fields. Models are judged by out-of-sample calibration and tracked against explicit confidence bins.
Q15: What must an asset owner have in place to do this well?
Talent, data, compute, governance.
Embedded data scientists working hand-in-hand with PMs
A pipeline that turns PDFs into structured, versioned records
Sufficient local compute for private LLM workflows
A written governance program with calibration, HIL, and board education
Q16: How do humans and models share responsibility for decisions?
Models prepare and score. Humans decide. Deep-learning recommendations run in parallel with investment-team decisions until the evidence base is large and stable. Overrides are documented like any other decision.
Q17: What does “good enough to ship” look like for productionization?
Stable extraction accuracy on key fields (measured against human labels)
Demonstrated calibration at chosen confidence thresholds
Documented decision scope and escalation paths
Board-level fluency and sign-off on policy
Q18: What is the ultimate target state for the memo process?
End-to-end automation for first drafts: models fetch, extract, analyze, and assemble a complete memo with sources, tables, and attribution. PMs then edit for judgment, risk, and fit—without spending time on retrieval, reformatting, or basic calculations.
Mind Map
Please share if you know of a tool capable of creating clean, professional looking mind map graphics. We lightly played around with Mermaid and that didn’t cut it.
I. Central Theme
A. One‑line Summary
AI at PSPRS centers on two pillars: Operational Efficiency and Decision Quality, under a clear governance program.
B. Why It Matters
Free investment staff from high‑volume, low‑value work.
Improve screening and underwriting rigor with calibrated models.
Build trust with stakeholders via documentation and education.
II. Operational Efficiency (RPA → Extraction → Drafts)
A. Document Ingress
Navigate proprietary portals and 2FA; bulk‑download data‑room materials (PPMs, DDQs, spreadsheets, filings).
B. Unstructured → Structured
Parse PDFs/OCR to extract canonical fields: partners_count; portfolio‑company metrics; fund_size; vintage_year; track‑record stats; compliance_officer; carry/“performance bonus” synonyms.
C. Normalization & Storage
Write extracted fields to a versioned, queryable database for analysis and reporting.
D. First‑Draft Investment Memos
LLM‑generated drafts assembled from extracted tables and standard sections; PMs review and edit.
E. Verification Loop
Human spot checks; precision/recall tracking on key fields; error triage back into prompts/parsers.
III. Decision‑Making (Analytics)
A. Machine Learning on Structured Data
Feature discovery and prediction when linear assumptions fail (small N, non‑normality, dependence).
B. Deep Learning on Unstructured Diligence
Pattern surfacing across documents/spreadsheets; acknowledge black‑box aspects.
C. Interpretability Aids
Use feature attribution (LIME/SHAP‑style) and activation‑pattern inspection where helpful.
D. Calibration & Parallel Runs
Track realized accuracy vs. stated confidence bins (e.g., 70%, 80%).
Keep DL recommendations in parallel with human decisions until evidence is strong.
IV. Governance & Oversight
A. Decision Logging
Every material recommendation records success definition and confidence; benchmark PMs and models over time.
B. Human‑in‑the‑Loop (HIL)
Define decision scope and override paths; models assist, humans decide.
C. Board Education
Build fluency with recurring briefings (semiannual planned); align vocabulary and risk controls.
D. Rollout Discipline
Start with verifiable tasks (labeling, math checks), then expand to predictive uses as calibration evidence builds.
V. Data & Information Architecture
A. Sources & Constraints
GP data rooms (PPMs, DDQs), filings (10‑Q), spreadsheets—heavy PDF bias; limited sample sizes in alternatives.
B. Field Dictionary & Schema
Standardize key entities (team, economics, track record, compliance, operating metrics) for reliable extraction and analytics.
C. Manager Web Portal (Planned)
After sufficient observations, publish the handful of factors that matter; enable self‑submission to speed screening.
VI. Tooling & Stack
A. Local LLMs
Run Llama/Gemma offline on PSPRS machines for security; point models at staged repositories.
B. Automation & Parsers
RPA for retrieval/staging; PDF/OCR parsers; templated memo assembler; internal database with provenance.
C. Multi‑Agent Vision
Ingest → Clean/Normalize → Analyze/Attribute → Draft Memo → Compliance → Humans.
VII. Compute & Deployment
A. Hardware Profile
~70B‑parameter local model; ~96 GB RAM for long‑context processing (suitable for long filings and multi‑doc synthesis).
B. Security Posture
Local‑first R&D; evaluate enterprise cloud solutions after proof of concept.
VIII. Screening & Workflow
A. Current Practice
Front‑loaded quantitative request to GPs; model‑assisted analysis of returns plus data‑room docs.
B. Evolving Filters
Identify the 5–6 most predictive fields once observations suffice; move to tighter pre‑filters.
C. Philosophy
80/20 filter—accept some false negatives; focus on quality of done deals.
IX. Stances & Opinions
A. Sentiment Analysis
Skeptical as an alpha source (causality may run trade → sentiment; misinformation and regulatory/flow confounds).
B. Explainability
Preferred when feasible; black‑box acceptable under calibration, clear scope, and HIL.
X. Talent & Organization
A. Embedded Data Science
Two data scientists (investor→DS; DS→investing) to counter institutional bias and align with PM workflows.
B. Stakeholders & Enablement
Board and executives with varied AI literacy—bring them along with education and transparent metrics.
C. External Expertise
Former PM (computer‑science focus) consulting on LLM use cases.
XI. Roadmap & Status
A. Now
Authorization to run local LLMs; R&D on extraction and memo drafting; verification‑first approach.
B. Next
Semiannual board education; portal design; progressive expansion of model scope; continue parallel runs.
C. Later
Evaluate enterprise cloud; scale multi‑agent workflow.
D. End‑State Goal
Remove low‑value, high‑volume tasks; humans focus on interpretation and judgment.
XII. Metrics & KPIs
A. Efficiency
Cycle time (access → first draft); docs/fields processed per day; staff hours saved.
B. Quality
Extraction precision/recall on key fields; memo edit distance (model draft → final).
C. Model Performance
Calibration accuracy by confidence bin; stability over time.
XIII. Illustrative Anecdote (Color)
A. Worst Pitch
Formula 1 racetrack in Monterrey; glossy pitch books requested back—illustrates disciplined triage and scarcity realities.
Disclaimer: The information contained in this newsletter is intended for educational purposes only and should not be construed as financial advice. Please consult with a qualified financial advisor before making any investment decisions. Additionally, please note that we at AInvestor may or may not have a position in any of the companies mentioned herein. This is not a recommendation to buy or sell any security. The information contained herein is presented in good faith on a best efforts basis.