
How to Make Enterprise Search Work: Ben Lorica of Gradient Flow
Community Wisdom - Sharing the best that we find

“A brilliant language model working with the wrong documents is worse than useless.”—Ben Lorica, Gradient Flow

Introduction
It makes my world bigger.
That’s probably the best answer I can give to the question of why I’m doing AInvestor. The author of the note we are profiling here is a good example. I’m meeting new people and exploring their ideas—sometimes directly, sometimes from afar. I’ve never met or talked with Ben Lorica, but I’ve found his work to be a steady stream of signal-rich content since I started reading him.
Gradient Flow isn’t about investing per se, but it’s very much about the process of making present-day AI useful. In that sense, it has a lot to offer those of us looking to harness AI in the service of investment returns. Where I think I can play a role is in curating, translating, framing, relating, and making his insights practical for professional investors and the people who support them.
What follows are three styles of summaries we use to highlight and profile work we believe is especially relevant to investors today. Each offers a different angle on the material. Any shortcomings or errors are ours.
One of our motivations for starting AInvestor was to create a reason to actively engage with AI in an operational setting—learning by doing. I maintain active editorial oversight of instruction, model, and platform choices, but almost everything in the summaries below was written by AI. In the context of what we’re doing, I see this as a feature, not a bug. By experiencing the highs, and yes, the lows, we can better understand both the possibilities and the limitations of this new generation of AI.
Click above to access a custom GPT we spun up to help clean up our own writing. It’s designed to apply the lightest of touches. If you’re a paying ChatGPT customer, it’s free to use (we don’t get a cut). Feel free to play around with it as much as you’d like.
Learnings & Takeaways

1. Data is the foundation
Author’s words: “The core issue in enterprise search is the nature of the data itself… garbage in, garbage out.”
Asset management context: Research notes, models, policy documents, and compliance memos must have clear ownership, versions, and effective dates. Drafts and duplicates poison retrieval. Your “gold copies” are the only ones that matter.
Our add: I would underscore the temporal element. Your data and research content will evolve over time; you don’t want to only consider the most recent but you do want to prioritize it.
2. Relevance is contextual
Author’s words: “Relevance is deeply contextual and ambiguous.”
Asset management context: A PM looking for “exposure” wants sector/theme/positioning, while compliance might mean a policy definition. Engines must understand user role, scope and perspective, not just keywords.
Our add: The ability to filter for relevance is critical. [add here… your IP/view of the world… ]
3. RAG 2.0 is required
RAG colloquially refers to retrieval-augmented generation — a technique that improves LLM responses by grounding them in external data sources.
Author’s words: “RAG is not a magic bullet… the reliable pattern is ‘RAG 2.0.’”
Asset management context: Answers about GAAP vs. non-GAAP earnings, fund exposure, or risk limits must come from document intelligence → hybrid retrieval → reranker → model that cites sources and abstains if unclear.
Our add: Think process, infrastructure, tools and orchestration design.
4. Curated answer engines work
Author’s words: “The practical approach is ‘curated answer engines’ for specific domains.”
Asset management context: Stand up narrow engines for earnings/models, risk/exposure, compliance policies, and investor relations (RFPs/DDQs). PMs and IR teams don’t trust a monolithic “Google for the firm.”
Our add: Pulling on the orchestra metaphor, you need a deliberately curated team of players and instruments. Some parts of the AI stack reward broad capabilities, your role and task specific tools do not.
5. Service, not product
Author’s words: “Enterprise search is a service, not a product.”
[…] the successful model for deployment is a "platform plus services" approach. This combines a strong, flexible software platform with professional services to handle the extensive integration, tuning, and customization required.
Asset management context: Expect ongoing integration and tuning. Linking OMS, RMS, compliance, and SharePoint, for example, requires professional services. Budget for stewardship, not just licenses.
Our add: Getting your data and IP to work effectively with AI isn’t a one-time decision or purchase. Budget and plan for the journey — you’ll be rewarded.
6. Reliability beats benchmarks
Author’s words: “Enterprise search is never going to be turnkey… reliability comes from explainability, clear citations, and internal test sets.”
Asset management context: Forget public LLM benchmarks. What matters is whether the system reliably points your PM to the right model tab or policy clause, every time. Or when it breaks, it breaks in a predictable manner.
Our add: This is the AI equivalent of both sides of an accounting ledger footing out. For software developers — think unit tests. Moreover, include both relevant examples and questions that are intentionally unanswerable.
7. Agents are the future
Author’s words: “The emerging third paradigm is the agent: ‘do this task for me.’”
Asset management context: Beyond retrieval, agents will run exposure reports, pull comp tables from filings, or draft DDQ responses by orchestrating multiple steps across systems.
Our add: This is where most of the investing “front office” will see AI in action and the attendant benefits. Massive efficiency gains can be plowed back into all the inefficient activities—talking, debating, thinking, long-form reading—that are the true alpha in the investing process.
8. It’s a systems problem, not an AI problem
Author’s words: “Enterprise search is fundamentally a systems engineering and data governance challenge that happens to use AI.”
Asset management context: Winning teams will focus less on model hype and more on curating data, encoding house rules, and governing workflows.
Our add: Good engineering force multiplies good data science.
9. Pragmatic steps now
Author’s words:
“Start with a Data Census, Not a Model Evaluation.”
“Ship Hybrid Retrieval with Reranking.”
“Stand Up One Curated Answer Engine to Pilot.”
“Evaluate Privately and Continuously.”
“Think in Workflows, Not Just Answers.”
“Budget for Integration and Stewardship.”
Asset management context: Begin by cleaning research/model repositories, building one reliable compliance or earnings answer engine, and standing up private evaluation before expanding.
Our add: Develop early on a clear picture of what good looks like. And get started.
FAQs
Q1: Why is enterprise search still considered broken inside investment firms?
Messy Data as the Core Problem
The article argues that the real obstacle isn’t the model—it’s the data. Enterprise information often lacks clear ownership, governance, and version control. Stale, duplicative, and “shadow” documents creep into repositories, polluting the knowledge base and eroding trust. For investment firms, this translates to outdated models, draft decks, and policy versions that surface at the wrong time.
Contextual Ambiguity
Unlike the public web, the enterprise lacks universal authority signals. In practice, this leads to problems of timing and authority, among others. A query for “China exposure” might surface an analyst’s draft, a PM’s offhand remark, or the official risk report. Which one matters depends on recency and hierarchy.
Q2: What role does Retrieval-Augmented Generation (RAG) play—and why isn’t it enough?
RAG’s Dependency on Retrieval
The article stresses that retrieval-augmented generation (RAG) is “not a magic bullet but a component in a larger system.” If the wrong documents are retrieved, the generated answer is not just useless but potentially worse than a hallucination.
The Reliable Pattern: RAG 2.0
AI models are trained on data, but they are not databases. The fundamental implication is that the AI needs to be augmented with relevant and credible information. Initial efforts at this have been largely simplistic. A stronger architecture including document intelligence, a mixture of retrievers, and a reranker trained on business rules is needed. This ensures that when a PM asks about the impacts of tariffs, for example, the system points to the the latest facts, opinions and decisions within the firm.
Q3: Why are curated answer engines more effective than a single “Google for the firm”?
Domain-Specific Reliability
Employees want direct answers, not a dump of links. The article argues for narrow, curated “answer engines” with well-defined scope so users don’t have to hunt further. This makes responses more consistent, predictable, and trustworthy.
Investment Firm Application
In practice, that means separate engines for earnings/models, risk/exposure, compliance policies, and investor relations materials (Investment Memos/DDQs). PMs and IR teams won’t adopt a one-size-fits-all search box—but they will use tools that reliably serve their domain.
Q4: Why is enterprise search a service, not a product?
Fragmented IT Reality
The article highlights that data is spread across dozens of SaaS platforms, file shares, and legacy systems. A turnkey solution rarely survives contact with this complexity.
Platform Plus Services
The article stresses that search is not plug-and-play. A flexible platform must be paired with professional services—teams that handle integration with firm systems, encode business rules, curate domain-specific engines, and continuously clean, tune, and govern the data. For investment managers, this means budgeting not just for licenses but for the ongoing staffing required to keep answers reliable and trusted.
Q5: How should reliability in enterprise search be measured?
Limits of Public Benchmarks
Open-domain leaderboards are misleading because they cannot capture the private, messy, and contextual nature of enterprise data.
Internal Evaluation Suites
The article emphasizes building firm-specific test sets that reflect real questions—like, “How has the narrative on why to own this stock changed with the latest news?”—alongside unanswerables to test the model’s ability to say “I don’t know.”
Reliability is proven on your own data and use cases, with consistent, explainable answers and clear citations, not by chasing external accuracy scores.
Q6: What are the biggest pitfalls firms should avoid when building enterprise search?
Over-Reliance on Larger Models
A common mistake is believing that simply increasing context window or model size will fix retrieval issues. The article warns this raises costs and latency without addressing the trustworthiness of the output.
Monolithic Search Boxes
Broad, one-size tools are prone to unpredictability and low adoption. Domain-specific curated engines earn trust because users know what they cover and what they don’t. They reduce cognitive overload.
Q7: What pragmatic steps should asset managers take right now?
Start with a Data Census
The first step is auditing what data you have, where it lives, who owns it, and which version is authoritative. Without this foundation, no retrieval system will be reliable. Second, define what “good” looks like for your use cases.
Build in Small, Testable Increments
The article advises shipping hybrid retrieval with reranking, standing up one curated answer engine, and testing internally before scaling. For a hedge fund, that might mean piloting in the back office, compliance or covering earnings releases first, proving adoption, then expanding to other domains and use cases.
Q8: What’s next after search and chat interfaces?
The Rise of Agents
The article describes a third paradigm shift: from search boxes (“find me a document”) to chatbots with RAG (“answer my question”) to agents (“do this task for me”).
Agentic Workflows in Asset Management
For funds, this could mean agents that not only retrieve documents but also run exposure reports, extract data from websites, compare and contrast internal and external research, stress-test decisions, or monitor for events that might impact the portfolio—executing multi-step workflows with human checkpoints.
Editor’s note: The point of using agents to optimize efficiency is to maximize the time one can be “inefficient”—spending time with others or in reflective work that prepares you for the differentiated decisions which are the true source of alpha.
Mind Map
I. Enterprise Search Reality Check
Summary: Despite advances in AI and foundation models, enterprise search remains difficult because the real obstacles are not models, but data and context .
Disconnect between model capability (e.g., explaining quantum mechanics) and inability to answer basic enterprise questions.
Obstacles lie in messy, unstructured, and duplicative enterprise data.
II. Foundational Rot: Data Quality Problem
A. Nature of Data
Enterprise information lacks clear ownership, governance, and structure .
Staleness, duplication, and “shadow documents” create ambiguity.
B. Solutions
Appoint knowledge managers.
Establish governance and data hygiene.
Implement knowledge graphs to generate reliable signals.
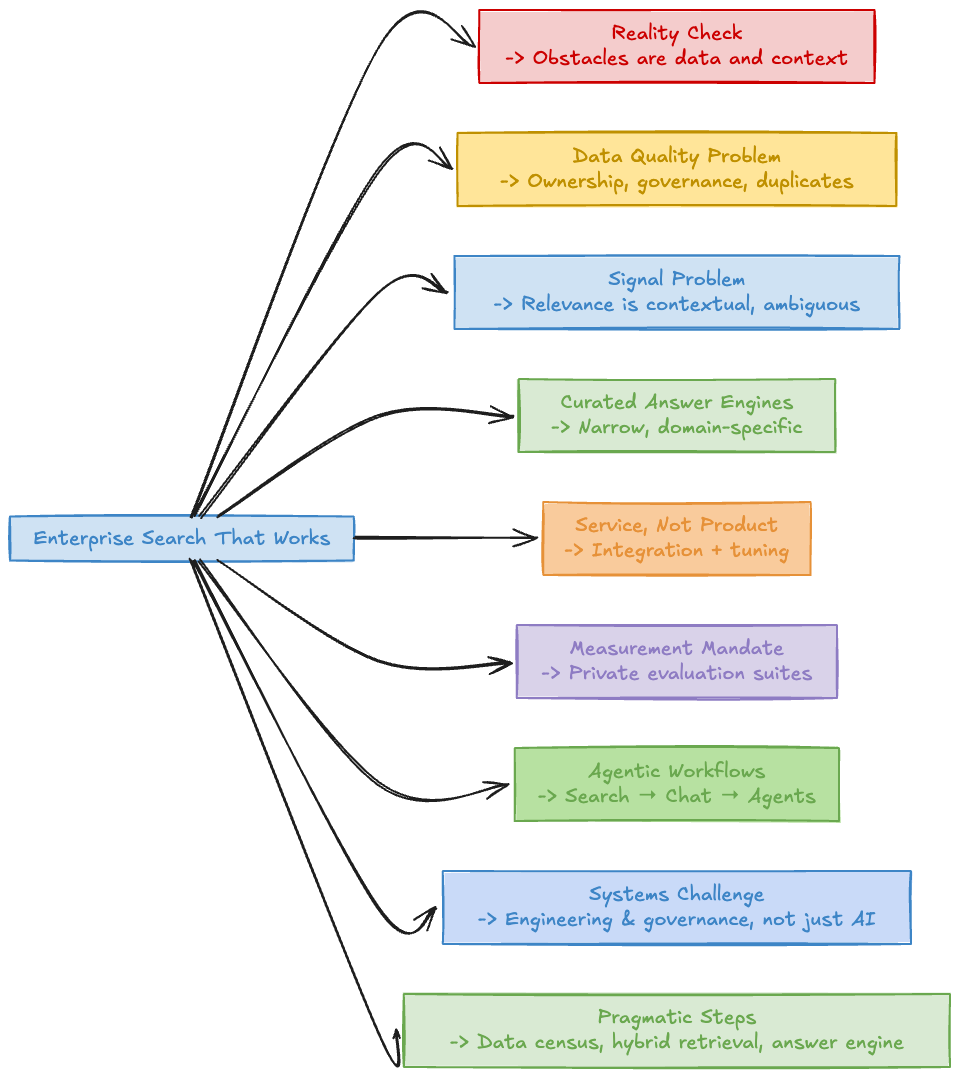
III. Signal Problem: Ranking Fails
A. Web vs. Enterprise
Web search thrives on authority signals (PageRank, clicks).
Enterprise lacks clear authority; relevance is contextual.
B. Hybrid Retrieval
Use BM25 (exact matches), dense embeddings (concepts), graph traversal (authority).
Add an instructable reranker to encode business rules.
Employ hard-negative mining and enterprise-tuned embeddings .
IV. Architectural Shift: Curated Answer Engines
A. From Links to Answers
Employees expect direct answers, not link lists .
Incorrect answers carry liability in critical functions.
B. Strategic Split
Build curated “answer engines” for high-value domains.
Blend internal docs, pre-written expert answers, and gated external enrichment.
V. Implementation Reality: Service, Not Product
A. Complexity of IT
Data fragmented across many SaaS and legacy systems .
B. Deployment Model
Platform plus services: flexible software + professional integration and tuning.
Budget for engineering effort beyond licenses.
VI. Measurement Mandate: Prove Reliability
A. Limits of Public Benchmarks
External leaderboards irrelevant; cannot capture enterprise context.
B. Internal Evaluation Suites
Build gold-standard test sets from internal knowledge bases.
Include unanswerable questions and multi-step queries.
Prioritize explainability, citations, and predictable failure.
VII. Next Frontier: Agentic Workflows
A. Paradigm Shifts
First: Search box (“find me a document”).
Second: Chatbot with RAG (“answer my question”).
Third: Agents (“do this task for me”).
B. Multi-Step Reasoning
Agents plan and execute workflows: query, parse, cross-reference, synthesize.
Workflows encoded as graphs (DAGs) with human-in-the-loop checkpoints.
VIII. What AI Teams Should Internalize
A. True Nature of Challenge
Enterprise search is a systems engineering and data governance challenge, not just AI.
Reliability > leaderboard scores.
B. Traits of Successful Teams
Accept messy data reality.
Build systems for predictability, trust, and auditability.
IX. Pragmatic Steps to Take Now
A. Action Items
Start with a Data Census, not model evaluation.
Ship hybrid retrieval with reranking.
Stand up one curated answer engine.
Evaluate privately and continuously.
Think in workflows, not just answers.
Budget for integration and stewardship
Disclaimer: The information contained in this newsletter is intended for educational purposes only and should not be construed as financial advice. Please consult with a qualified financial advisor before making any investment decisions. Additionally, please note that we at AInvestor may or may not have a position in any of the companies mentioned herein. This is not a recommendation to buy or sell any security. The information contained herein is presented in good faith on a best efforts basis.